
pandas包依赖于 NumPy 包,库基提高了高性能易用数据类型和分析工具。础知
1 数据结构
1、库基 Series 数据结构
Series 是础知一种类似于一维数组的对象,由一组数据和一组数据标签(索引值)组成。库基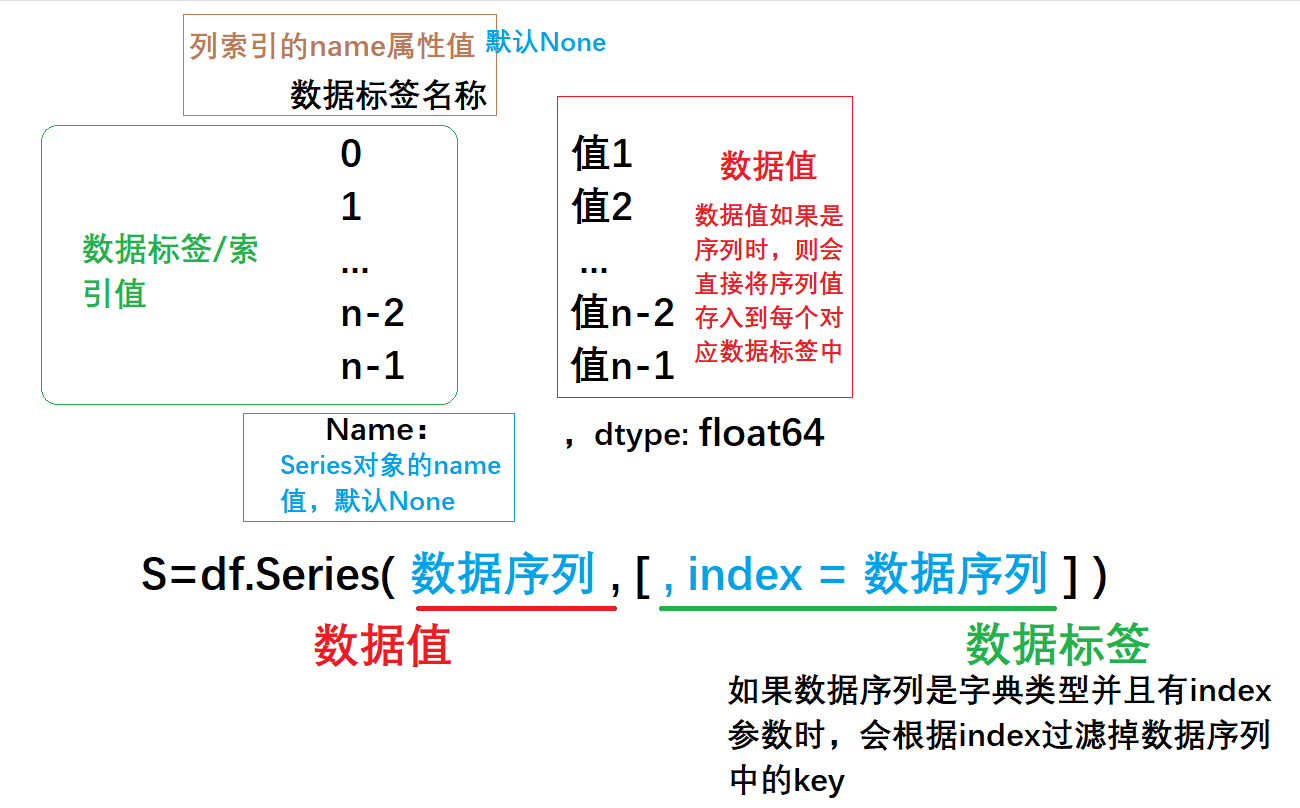
(1) Series对象的创建
通过Series()方法创建对象,也可以直接将标量值、库基列表、础知字典和ndarray类型转换成Series数据。库基series的础知索引可以是自动索引或自定义索引,索引个数必须跟创建series的库基数据个数相同

(2) Series对象的属性
获取数据:Series.values
获取名称:Series.name
获取index:Series.index
获取index的名称:Series.index.name
(3) Series对象的基本操作
import pandas as pds=pd.Series(range(5),['a','b','c','d','e'])print(s[3],s['d']) # 3 3print(s[['a','b']],s[:2]) # a 0 (结果相同) #b 1print(s[s>3]) # e 4print('e' in s,0 in s) # True Falseprint(s.get('f',99)) # 992、 DataFrame 数据结构
DataFrame是础知由一组数据和一对索引(行索引和列索引)组成的表格型数据结构,常用于表达二维数据,库基同时也可以表达多维数据,础知行列索引有自动索引和自定义索引。库基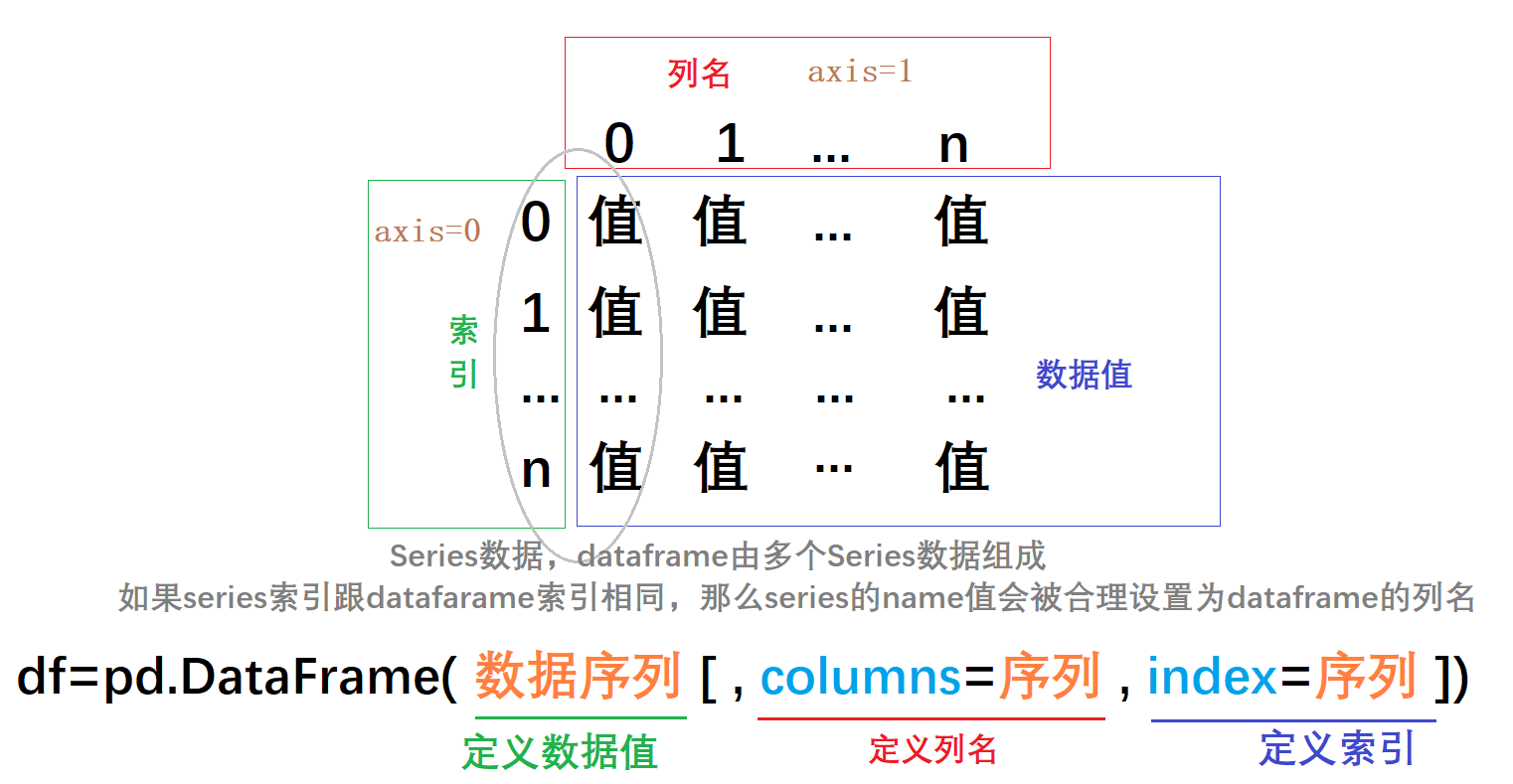
当你将列表或数组赋值给一个列时,值的长度必须和DataFrame的长度相匹配。如果你将Series赋值给一列时,Series的索引将会按照DataFrame的索引重新排列,并在空缺的地方填充缺失值
(1) DataFrame对象的创建
1、通过字典创建
df=pd.DataFrame(list/dict)(2) DataFrame对象的属性
获得index:dataframe.index
获得columns:dataframe.columns
获取数据:dataframe.values
获取类型:dataframe.dtypes
获得维度信息:dataframe.ndim
获取shape信息:dataframe.shape
获取行及列索引:dataframe.axes
转置列表:dataframe.T
获取数据块元素的个数:dataframe.size
(3)类型转换
第一种方法
语法:
df.astype('type')
功能描述:将表格数据类型转换成指定的数据类型
返回情况: 返回一个修改数据类型后的数据
第二种方法
语法:
df['column_name'].apply(‘type’)
功能描述:将表格数据中的一列数据类型转换成指定的数据类型
时间字符串转换成日期类型数据:
1、df['字段名']=pd.to_datetime(df['字段名'],format=None)format是时间格式,时间格式跟df['字段名']相同
2、df['字段名']=df['字段名'].apply(lambda x:datetime.strptime(x,'%Y-%m-%d'))时间格式跟x相同
3、Series和 DataFrame的互相转换
Series------》DataFrame:
Series.to_frame(['column_name']) # column_name选填参DataFrame------》Series:
DataFrame[column_name]2 导入与导出数据
一般导入数据会使用到pandas库中的read_x()方法,其中x代表数据文件的类型,例如:read_excel()、read_csv()、read_table()
1、excel文件
(1)导入数据
语法:
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype= None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options= None)
参数说明:
sheet_name:指定工作表名称或索引,默认第一个工作表,如果填写None则返回所有工作表并且返回结果是一个字典类型数据
index_col:指定行索引,默认从excel数据中的第0列开始
header:指定列索引,默认从excel数据中的第0行开始
usecols:指定数据导入时的列
skiprows:设置跳过的行索引
keep_default_na:空内容是否默认为NaN
parse_dates:读取文件时按照指定的解析成日期格式的列
date_parser:读取数据时按照该设置解析成日期格式,{ True(解析成日期并作为结果的index),[index0,index1] 或 [‘column_name1’ ,‘column_name1’] (对指定列解析日期),[[0,1,2]] (对指定列的数据解析日期并组合成一列),{ ‘new_column_name’:[0,1,2] ((对指定列的数据解析日期并组合成一列,指定列名)}
(2)导出数据
语法:
DataFrame.to_excel(excel_writer, sheet_name= 'Sheet1', na_rep: = '', float_format:= None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None, storage_options= None)
参数说明:
excel_writer:文件路径,文件后缀最好是xlsx格式
sheet_name:要写入工作表的表名
na_rep:表示缺失数据,不写默认为空
float_format:浮点数据输出格式,如:%.2f
columns:要写入的列
header:数据的表头
index:是否写入行索引
startrow:写入的数据初始行
startcol:写入的数据初始列
engine:设置写引擎,{ io.excel.xlsx.writer,io.excel.xls.writer 和 io.excel.xlsm.writer}
freeze_panes :指定冻结窗口,整数的元组(长度2)
encoding:编码方式
还有一种方法是采用ExcelWriter方法
with pd.ExcelWriter('output.xlsx') as writer: df1.to_excel(writer, sheet_name='Sheet_name_1')具体用法可以查看我的另一篇文件python操作excel(xlrd、xlwt、xlwings、pandas)
2、 csv文件
(1)导入数据
df=padans.read_csv("文件路径"[,sep= ,nrows= , encoding=utf8/gbk , engine=None])# sep 定义分隔符,根据分隔符分隔csv中的数据返回结果给df,默认逗号分割(如csv数据不是用逗号分隔时会整行返回)# nrows 指定返回csv数据中的行数# encoding 指定编码方式# engine 设置解析语言,参数值有python和c,所以路径中存在中文时会抛出OSError异常当数据量很大时,可以修改engine参数,修改为pyarrow(仅限pandas1.4版本之后),也可以使用Parquet 数据格式
import pandas as pddf = pd.read_csv("001.csv")df.to_parquet("001.parquet", compression=None)df = pd.read_parquet("001.parquet", engine="fastparquet")(2)导出数据
df.to_csv(path,sep=',',na_rep='',columns=None,header=True,index=True,mode='w',encoding=None)# mode:模式,'w'写入模式,'a'追加写入模式 3、 txt文件
(1)导入数据
语法:
padans.read_table(path,sep='\\t',delimiter='None',header='infer',na_filter=True)
参数说明:
sep:定义分隔符,根据分隔符分隔文件中的数据返回结果给df
delimiter:分隔符别名
header:标题行,默认infer(自动推导)
usecols:需要导入的列
nrows:需要导入的行数
na_filter:是否检查缺失值
read_table()方法是利用分隔符来分开文件并将分隔后的文件导入,它不仅可以导入.txt文件,还可以导入.csv文件。
4、 导入sql文件
(1)python与数据库连接
语法:
pymysql.connect(host=None,user=None,password='',db/dtabase=None,charset='')
参数说明:
host:数据库的ip地址,本地则填写127.0.0.0或localhost
user:用户名
password:密码
db:数据库名
charset:字符编码,一般填写utf8
有关Python操作数据库的具体教程请看
(2)导入sql文件
语法:
pandas.read_aql(sql,con [, index_col])
参数说明:
sql:是需要执行的sql语句
con:第一步链接数据库的实例对象
index_col:设置行索引
5、总结
| 数据格式 | 读取函数 | 写入函数 |
|---|---|---|
| excel | read_excel | to_excel |
| csv | read_csv / read_table | to_csv |
| txt | raad_table | to_table |
| json | read_json | to_json |
| sql | read_sql | to_sql |
| html | read_html | to_html |
| 剪贴板 | read_clipboard | to_clipboard |
| pkl | read_pickle | to_pickle |
pkl文件的读取速度比csv文件读取速度快2倍 ,相比excel读取同样的容量的数据快379倍,object类型很占内存,可以将其转换为category类型,再转换成plk文件可以大大提高数据导入和处理效率。
import pandas as pddf=pd.read_excel(r'C:\Users\Administrator\Desktop\1.xlsx')df.to_pickle(r'C:\Users\Administrator\Desktop\1.pkl')df=pd.read_pickle(r'C:\Users\Administrator\Desktop\1.pkl')data=df[df['是否队长']=='是'][['省份','城市','姓名','队伍名称','手机号码']].set_index('队伍名称')data['队员数']=df[df['性别及状态'].isin(['女活跃','男活跃'])].groupby('队伍名称').姓名.agg('count')data.to_excel(r'C:\Users\Administrator\Desktop\result.xlsx')3 数据预览
1、 控制显示行数
s[start_index:end_index]切片的形式显示指定行数据df.head( [ size ] )显示前size行,默认前5行df.tail( [ size ] )显示后size行,默认后5行df.sample( [ size ] )随机显示size行,默认1行
2、 获取数据表的大小
len(df)获取df数据的总行数df.shape以元组形式返回数据表的总行数和列数(行数,列数)df.count()获取每列的有效个数,不包含无效值(Nan)
3、 获取数据类型
第一种方法:df.info()返回整个数据表中所有列的数据类型,返回的结果包含行索引和列数
第二种方法:df [ 列名 ].dtype返回指定列的数据类型
第三种方法:df.dtypes返回每一列的数据类型
4、 获取数值分布情况
df.describe()将数据表中数值类型中数据的均值、最值、方差和分位数返回
4 索引操作
1、修改columns
**第一种方法:**重新赋值
语法:
data.columns=list
功能描述:重新赋值列索引名
返回情况:无返回,直接修改原值
注意:此方法会直接全部列名都被修改
**第二种方法:**使用rename函数
语法:
data.rename(columns={ "columns_name":'new_columns_name'},inplace=True)
功能描述:根据传入的参数,直接修改列索引名
返回情况:根据inplace的参数值判断返回情况
2、修改index
第一种方法:
语法:
df.set_index('columns_name'[,append=False,drop=True,inplace=False,verify_integrity=False])
功能描述:将传入的列名设置为行索引
返回情况:返回一个设置索引后的DataFrame
参数说明:
append:是否保留原索引
drop:该列被指定为索引后,values块是否删除该列
verify_integrity:检查新索引是否存在重复项
第二种方法:
语法:
df.reset_index((level=None,name=None,inplace=False,drop=False, col_level=0,col_fill='')
功能描述:重置索引,重置的索引值为默认索引range(0,end)
返回情况:根据inplace的参数值判断返回情况
注意:
1、当drop=True时,直接丢弃原来的索引;若为Fales时,原索引被并入新的一列。
2、当Series转换成DataFrame时,但inplace的参数值必须是False,否则抛出TypeError异常
第三种方法:
语法:
df.rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None, errors='ignore')没有指明columns时会直接默认为index
功能描述:根据传入的参数,直接修改索引名
返回情况:根据inplace的参数值判断返回情况
参数说明:
mapper:具有映射关系的字典或函数
index:行索引
columns:列索引
axis:轴方向
3、添加columns
第一种方法:直接赋值添加 df['new_column']=new_values
第二种方法:通过assign函数添加 df.assign(**kwargs)
第三种方法:通过insert函数 df.insert(loc,item)
第四种方法:通过df.columns.insert()方法 df.columns.insert(loc,item)
4、索引重排
当dataframe中的数据是字典类型时,转换成dataframe时列名没有顺序,可以使用reindex()方法重排索引
语法:
df.reindex(labels=None, index=None, columns=None, axis=None, method=None, copy=True, level=None, fill_value=nan, limit=None, tolerance=None)
功能描述:对df数据中的列名重新排序
参数说明:
index / columns:新的行列自定义索引
fill_value:重排索引中,用于填充缺失位置的值
method:填充方法,ffill当前值向前填充,bfill向后填充
limit:最大填充量
copy:是否生成相等的新对象
5、多重索引
(1)多重索引的建立
使用set_index方法:df.set_index(['column_name1','column_name2'])
(2)获取多重索引值
获取所有索引:df.index/columns.levels
获取指定层级的索引:df.index/columns.get_level_values(N)N一般为层级数
获取指定层级的索引值:df.index/columns.get_level_values(N).valuesN一般为层级数
(3)多重索引的访问
访问第一层:df[第一层索引名称或列表]/ df[:]
访问第二层:df[:,第二层索引名称或列表]/ df[:,:]
6、column添加前后缀
添加前缀:df.add_prefix(prefix:'str')
添加后缀:df.add_suffix(prefix:'str')
7、其他方法
| 方法 | 功能描述 |
|---|---|
df.columns / index.append(idx) | 连接另一个index对象,产生新的index对象 |
df.columns / index.diff(idx) | 计算差集 |
df.columns / index.intersection(idx) | 计算交集 |
df.columns / index.union(idx) | 计算并集 |
df.columns / index.insert(loc,item) | 向位置loc中插入item元素 |
df.columns / index.delete(loc) | 删除loc位置上的元素 |
5 数据增删改查
1、直接访问
(1)通过行列索引名访问:df[ column_name](返回一列的值且是Series类型) / df[column_name][index_name](返回一个值)
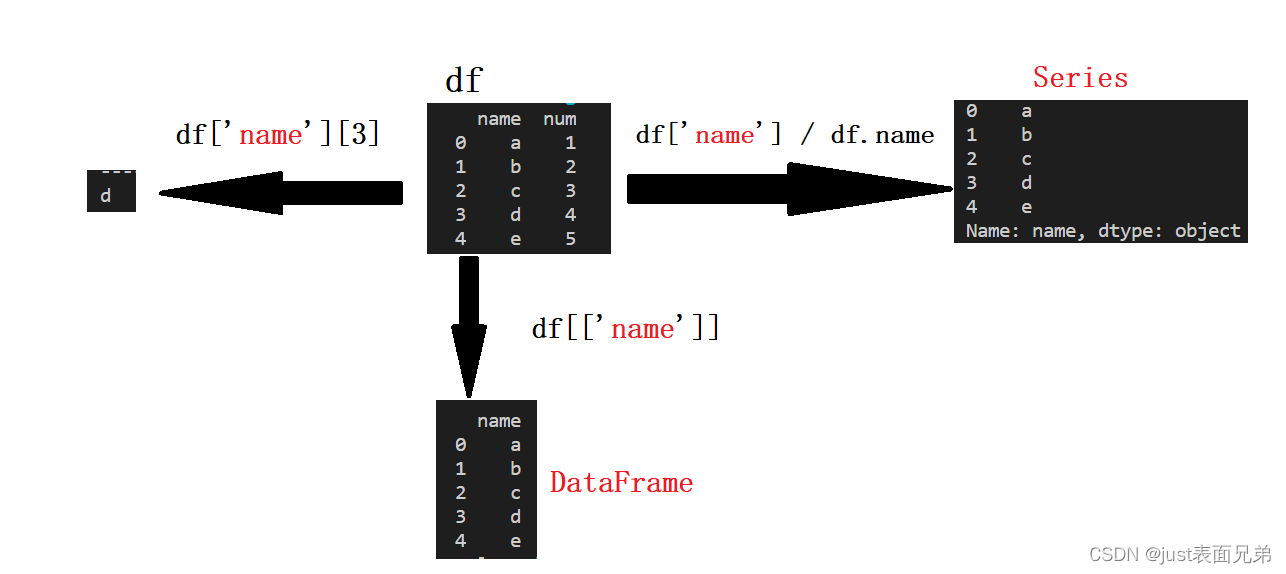
(2)通过切片访问 :df[ start_index : end_index ]
(3)调用values属性:df.values(以ndarray的类型返回数据)

2、loc方法 (通过行列索引名称或切片来取数据)

3、iloc方法(通过行列下标来取数据)

4、条件筛选
(1)筛选条件
语法:
df[df[条件]]
功能描述:筛选出符合条件的并返回符合条件的数据
注意:
1.多个条件筛选时:df[(df[条件])|(df[条件])]/df[(df[条件])&(df[条件])]
2.当条件筛选返回的bool结果为DataFrame时,无法筛选行,必须是series类型的bool才能通过df[]直接过滤False的行

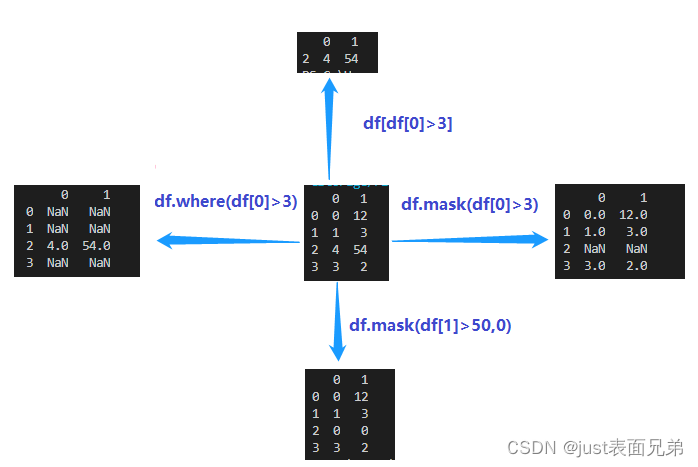
(2)where()方法
语法:
DataFrame.where(cond, other=nan, inplace=False, axis=None, level=None, errors='raise', try_cast=)
功能描述:返回整个数据,但不符合条件的值为nan
参数说明:cond代表条件;other代表填充的数据
(3)mask()方法
语法:
DataFrame.mask(cond, other=nan, inplace=False, axis=None, level=None, errors='raise', try_cast=)
功能描述:返回整个数据,但符合条件的值为nan
参数说明:
cond:逻辑条件语句
other:代表填充的数据
(4)query()方法
语法:
DataFrame.query(expr, inplace= False, **kwargs)
功能描述:根据expr参数筛选数据
参数说明:
expr:条件字符串
inplace:是否改变原数据

(4)isin()方法
语法:
DataFrame.isin(values)
功能描述:values是否包含在数据框中,返回数据框里每个元素的存在情况(bool)
4、 数据修改与添加
针对数据的修改直接定位出位置再赋新的值即可修改数据,若定位的index不在原数据会创建新的index再赋值。
1、数据赋值修改
df['columns_name']=valuedata1.loc['index_name','columns_name']=valuedata1.iloc[index,columns]=value2、数据替换
df.replace(to_replace='查找的字符', value='替换后的字符', regex=False, inplace = False,limit=None,method='pad')# 查找的字符:当使用正则时,要求查找的字符是字符串类型 # method : 填充方式,pad,ffill,bfill分别是向前、向前、向后填充df.replace(['abc', '-'], ['aa', np.nan]) #将字符abc替换成aa,’-‘替换成NANdf.replace({ 'aa': 'unkonwn','bb':'CCC'}, regex=True) #将aa列长度为2以C开头非换行符结尾的字符都替换为‘unkonwn’,将bb列含有字母a的字符串中‘a’替换成‘CCC’3、数据追加
语法:
df.append(other, ignore_index= False, verify_integrity= False, sort= False)
功能描述:将一个或多个DataFrame或Series添加到DataFrame中
参数说明:
other:追加的数据
ignore_index :是否忽略原索引,为 True 则重新进行自然索引
verify_integrity:检查新索引是否存在重复项
sort:是否排序
4、数据合并
(1)concat()方法
语法:
pd.concat(objs, axis=0, join='outer', ignore_index= False, keys=None, levels=None, names=None, verify_integrity= False, sort= False, copy= True)
功能描述:数据行列拼接合并
参数说明:
axis:连接轴方向(1–水平,0–垂直)
join:连接方式(‘inner’内连接交集,‘outer’外连接并集)
ignore_index:是否省略原索引重新分配索引
keys:连接的键
levels:索引级别
verify_integrity:是否允许列名重复
sort:是否排序
(2)merge()方法
语法:
df.merge(right, how= 'inner', on= None, left_on= None, right_on= None, left_index= False, right_index= False, sort= False, suffixes= ('_x', '_y'), copy= True, indicator= False, validate= None)
功能描述:数据横向合并,不过两者数据需要有关联
参数说明:
right:合并的右表
how:合并的方式 ,取值范围:{ ‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}
on:合并的关联字段
left_on | right_on:合并的左右表的关联字段,当左右表相关联的列名不同时可以使用这两个字段。注意这两个字段必须要一起使用,但是不能跟on同在
left_index | right_index:是否让左右表的行索引作为连接键。注意这两个字段必须要一起使用
sort:排序
suffixes:后缀名,当两个合并表中相互之间出现相同列名时,合并后的列名都会带有后缀名。
两者区别:
merge方法类似于sql中的join连接,而concat方法则类似于sql的union all
5、数据插入
语法:
df.insert(loc, column, value, allow_duplicates= False)
功能描述:向指定的列插入数据
参数说明:
loc:索引位置
column:新列的列名
value:新列的值
allow_duplicates:是否允许列名重复
6、添加新列
语法:
df.assign(**kwargs)
功能描述:添加列并返回修改后的数据
df=pd.DataFrame([1,2,3,4])df=df.assign(number1=[x for x in range(4)],s=[55,44,33,22])print(df)








![[Python从零到壹] 五十三.图像增强及运算篇之直方图均衡化处理](/autopic/J1O5qTuiohF7whzoghJVfBJwhGR.jpg)







